在 webpack:如何解决浏览器缓存问题 文章里介绍了用chunkhash解决浏览器缓存问题,在那篇文章里默认把CSS文件一起打包进JS bundle文件中。
但在一般项目里面CSS的改动比较少,如果打包成JS bundle文件,再结合chunkhash,每次发布以后,虽然CSS文件没有改动,但是客户端还是需要重新下载这些样式文件。如果CSS文件过大的话,在一定程度上会影响性能。
接下来就介绍,如何在打包过程不把CSS 内联打包到JS bundle文件,而是直接提取生成单独的CSS文件,如果项目中CSS有更改,提出生成的CSS文件名也会带上不同的hashcode。
extract-text-webpack-plugin
在webpack中,是用 extract-text-webpack-plugin 这个plugin把样式提出成单独的css文件。
需要注意的是:
webpack3 提取 css 的 plugin 是 extract-text-webpack-plugin
webpack4 提取 css 的 plugin 是 mini-css-extract-plugin
这篇文章是基于 webpack3.10.0
具体用法如下:
const ExtractTextPlugin = require("extract-text-webpack-plugin");
module.exports = {
module: {
rules: [
{
test: /\.css$/,
use: ExtractTextPlugin.extract({
fallback: "style-loader",
use: "css-loader"
})
}
]
},
plugins: [
new ExtractTextPlugin("styles.css"),
]
}
第一种方式:ExtractTextPlugin 和 hash 结合使用
示例代码:angular-seed-project
完整webpack代码 webpack.bundle.js
两个js文件:
// css-extract-a.js,引用 a.css
// webpack build: extract css into .css file, no longer bundle into .js file
import aStyle from '../../assets/a.css'
console.log('this is a extract css file');
//css-extract-b.js, 引用 b.css
// webpack build: extract css into .css file, no longer bundle into .js file
import bStyle from '../../assets/b.css'
console.log('this is b extract css file');
两个 css 文件:
/**a.css**/
html {
font-size: 1em;
color: red;
}
/**b.css**/
html {
font-size: 2em;
color:blue;
}
webpack.bundle.js 文件如下:
entry: {
'extract-a': './src/app/bundle/css-extract-a.js',
'extract-b': './src/app/bundle/css-extract-b.js'
},
output: {
path: path.join(__dirname, '../build-bundle'),
filename: ' [name].[hash].bundle.js'
},
module: {
rules: [
{
test: /\.css$/,
use: ExtractTextPlugin.extract({
fallback: 'style-loader',
use: ['css-loader?minimize']
})
}
]
},
plugins: [
new CleanWebpackPlugin(['./build-bundle'], { root: path.join(process.cwd(), '') }),
new ExtractTextPlugin('[name]-[hash].css')
]
编译结果如下:
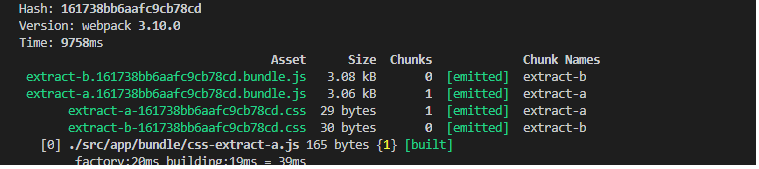
我们可以看到,生成了四个文件。两个.js bundle文件,两个.css文件,我们可以看到文件名中的hashcode完全一样。这个会导致每次发布,不管文件改没改,都会build成不一样的文件名,导致客户端重新下载所有文件,这个并不是我们想要的。
第二种方式,ExtractTextPlugin 和 chunkhash 结合使用
在 如何利用 webpack 解决浏览器缓存问题 文章中提到chunkhash可以根据源文件内容的改变,来决定最终bundle文件名是否需要更改,而且每个chunk文件中的hashcode都不一样。
webpack.bundle.js 文件如下:
entry: {
'extract-a': './src/app/bundle/css-extract-a.js',
'extract-b': './src/app/bundle/css-extract-b.js'
},
output: {
path: path.join(__dirname, '../build-bundle'),
filename: ' [name].[chunkhash].bundle.js'
},
module: {
rules: [
{
test: /\.css$/,
use: ExtractTextPlugin.extract({
fallback: 'style-loader',
use: ['css-loader?minimize']
})
}
]
},
plugins: [
new CleanWebpackPlugin(['./build-bundle'], { root: path.join(process.cwd(), '') }),
new ExtractTextPlugin('[name]-[chunkhash].css')
]
编译结果如下:
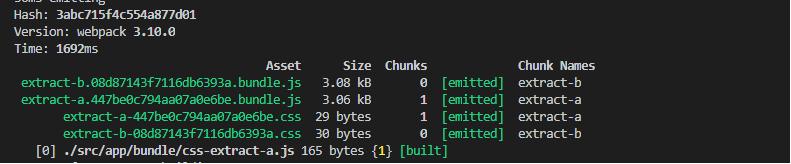
从上面的截图我们可以看到,入口文件对应的bundle文件hashcode是不一样的,这个好理解,因为用到了chunkhash。但是对应引用的css中的hashcode也跟bundle文件名一样。
总觉得不对劲,我们来尝试改下 a.css文件内容:
html {
font-size: 1em;
color: red;
line-height: 1em;
}
重新编译以后的结果:
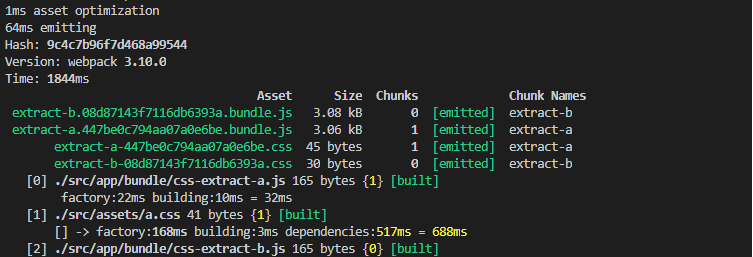
从上面截图可以看到,虽然a.css文件改过了,但是最后编译结果文件跟上一次没有任何区别。也就是说发布以后,客户端在缓存没过期的前提下,还是看不到更改以后的样式,显然这也不是我们想要的。
为什么会有这样的结果?仔细想一下,chunkhash 是基于入口文件来计算hashcode的,入口文件没有改动,那么最终的hashcode也不会改变。
我们想要的编译结果是:所有文件(.bundle.js/ .css)的hashcode都应该是独一无二的,并且不管是入口文件还是从他们提取的CSS文件有改动的话,那么对应的编译文件的hashcode也要跟着改变。
第三种方式,ExtractTextPlugin,chunkhash和contenthash结合使用
webpack.bundle.js 文件如下:
```js
entry: {
'extract-a': './src/app/bundle/css-extract-a.js',
'extract-b': './src/app/bundle/css-extract-b.js'
},
output: {
path: path.join(__dirname, '../build-bundle'),
filename: ' [name].[chunkhash].bundle.js'
},
module: {
rules: [
{
test: /\.css$/,
use: ExtractTextPlugin.extract({
fallback: 'style-loader',
use: ['css-loader?minimize']
})
}
]
},
plugins: [
new CleanWebpackPlugin(['./build-bundle'], { root: path.join(process.cwd(), '') }),
new ExtractTextPlugin('[name]-[contenthash].css')
]
编译结果如下:
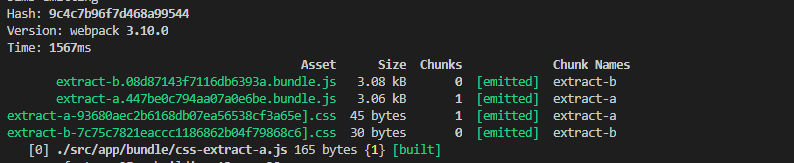
从上面的编辑结果中可以看到,所有文件的hashcode都不一样,而且任一文件有改动,编译以后,对应文件的hashcode也会发生改变。
这就完美解决了我们的缓存问题!!
hash chunkhash contenthash三者的区别
最后来总结一下 hash chunkhash contenthash 这三者之间的区别。
-
hash 是用来给本次build计算hashcode,所有的编译结果文件中的hashcode都会一样。
-
chunkhash 是用来给每个entry file计算hashcode,每个编译结果文件中的hashcode都是独一无二的。而且entry file任一文件改动,对应的bundle文件hashcode也会改动,否则就保持不变。
-
contenthash 是用来给ExtractTextPlugin提取的文件内容计算hashcode,注意只是基于提取内容,而不是整个chunk文件。