本文主要会介绍以下内容:
- HTTP/1.x 协议的性能缺陷
- 为了优化 HTTP/1.x 的网络性能问题,前端用到的黑魔法
- HTTP/2 新特性
- HTTP/1.x 的 keep-alive 与 HTTP/2 多路复用的区别
- HTTP/2 缺陷
HTTP/1.x 协议的性能缺陷
1. TCP 连接导致的性能瓶颈
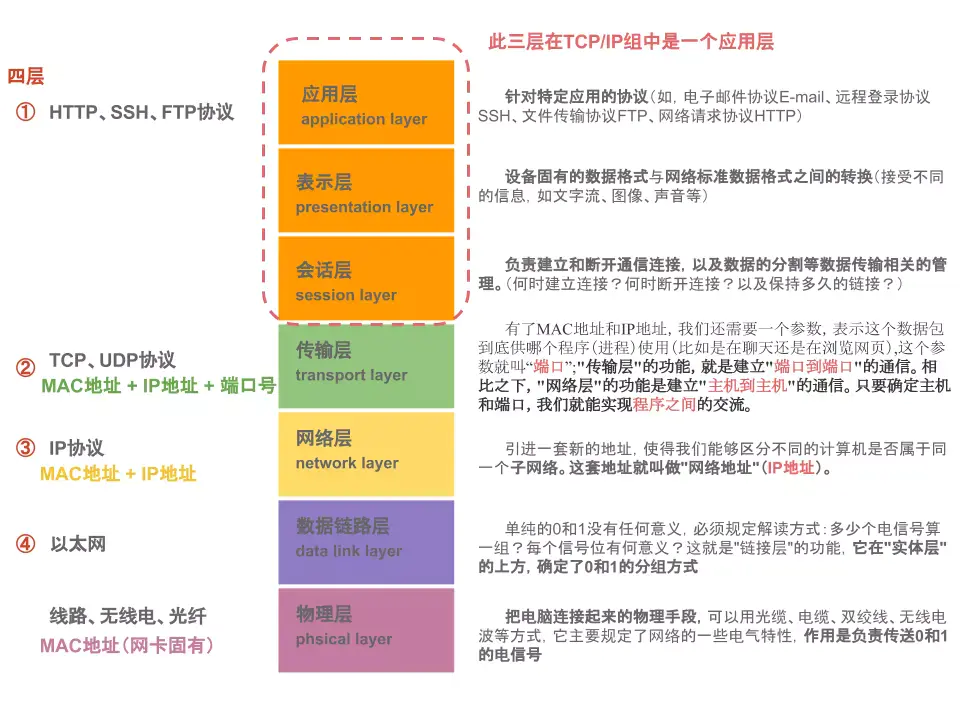
从上图可以看出,HTTP 的传输协议主要依赖于 TCP 来提供从客户端到服务器端之间的连接。TCP 建立连接有三次握手,加上 TCP 慢启动导致的传输速度低,打开和保持 TCP 连接在很大程度上影响着网站和 Web 应用程序的性能。
TCP 连接会随着时间自我调谐,起初会限制连接的最大速度,如果数据成功传输,会随着时间的推移提高传输的速度。这种调谐则被称为 TCP 慢启动。
在 HTTP/1.x 里有多种模型:短连接, 长连接, 和 HTTP 流水线。
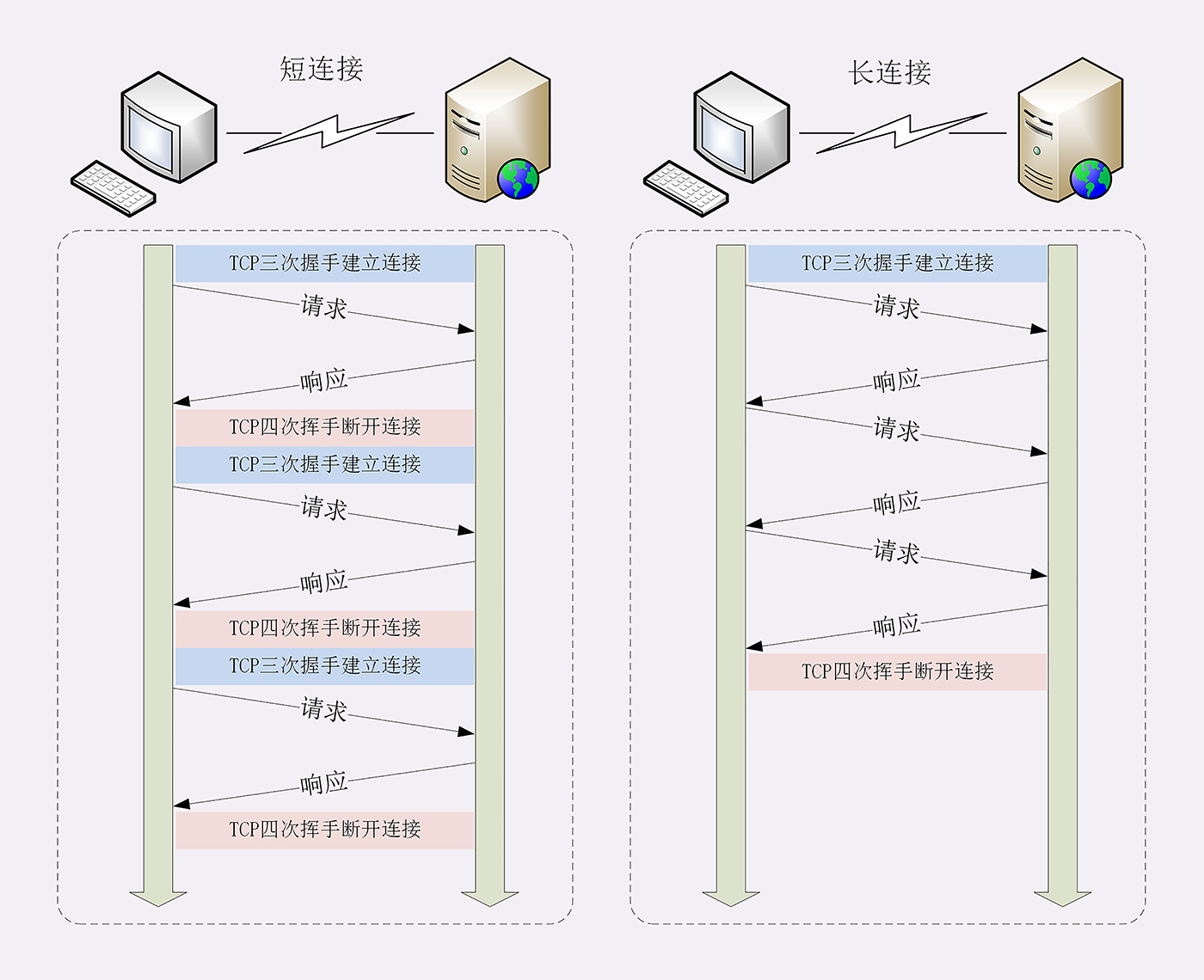
短连接是 HTTP/1.0 的默认模型,它每发一个请求时都会创建见一个新的 TCP 连接,收到 response 的时候就立马关闭连接,每次创建一个 TCP 连接都相当耗费资源,另外 TCP 连接的性能只有在该连接使用一段时间以后(慢启动)才能得到改善,可想而知这种方式的性能很差,现在基本不用这种方式。
在 HTTP/1.1 以后就有了长连接和流水线,长连接是指创建一个 TCP 连接后,可以保持连接完成多次连续的请求,减少了打开 TCP 连接的次数,在 HTTP/1.1 以后的版本是默认的长连接的模式,长连接的缺点是,就算在空闲状态,它还是会消耗服务器资源。长连接是通过 Keep-Alive消息头来控制。
流水线是在同一条连接上发出连续的请求,而不用等待应答返回,这样可以避免连接延迟。理论上这种方式是最有效的,实现流水线是复杂的:传输中的资源大小,多少有效的 RTT 会被用到,还有有效带宽,流水线带来的改善有多大的影响范围。不知道这些的话,重要的消息可能被延迟到不重要的消息后面。这个重要性的概念甚至会演变为影响到页面布局!因此 HTTP 流水线在大多数情况下带来的改善并不明显。HTTP/1.1 仍然需要 response 按请求发出的顺序返回,如果某个请求花了很长时间,就会阻塞其他的请求,另外,互联网上的服务器和代理服务器常常没有实现管道化特性,或者实现有问题,基本没有人用这种连接模型。
2. HTTP/1.x 队头阻塞(head of line blocking)
默认情况下,HTTP 请求是按顺序发出的。下一个请求只有在当前请求收到答应过后才会被发出,由于受到网络延迟和带宽的限制,如果某个请求花了很长时间,那么队头阻塞(head of line blocking)会影响其他请求。
3. 无状态:头部巨大且重复
由于 HTTP 协议是无状态的,每一个请求都得携带 HTTP 头部,特别是对于有携带 cookie 的头部,而 cookie 的大小通常很大,另外还有 User Agent、Accept、Server 等,通常多达几百字节甚至上千字节,但 Body 却经常只有几十字节
4. 明文传输:不安全
HTTP/1.1 在传输数据时,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份,这在一定程度上无法保证数据的安全性。HTTPS 解决了这个安全问题,但 TLS/SSL 建立连接的时候,需要四次握手,增加了 RTT(Round Trip Time),一定程度上也会影响性能。
5. 不支持服务器推送
HTTP/1.1 不支持服务器推送消息,因此当客户端需要获取通知时,只能通过定时器不断地拉取消息,这无疑浪费大量了带宽和服务器资源。
为了优化 HTTP/1.x 的网络性能问题,前端用到的黑魔法
基于 HTTP/1.X 的连接限制,前端在开发中过程要尽量减少网络带宽的占用,比如尽可能的减小文件的大小和减少请求次数,尽可能的减少 RTT(Round Trip Time),前端优化性能的黑魔法有:
- Bundling:使用 webpack 等工具打包,打包压缩多个 js 文件到一个文件中,以一个请求替代多个请求
- Code Splitting:在打包的过程中,将公用代码切割到一个文件中,这样只需要下载一份公用代码
- Minify,Uglify,Compression:减少文件大小
- Tree-shaking:打包过程中,把没有用到的代码剔除,也是为了减少文件大小
- Cache:使用缓存,减少跟服务端的通信,从而提高性能
- Lazy Loading 和 Preloading:减少第一时间的 HTTP 请求次数,提高首页加载的性能
- Service Worker:减少跟服务端的通信,从而提高性能
- 使用多个域名:现在浏览器对同一个域名的 TCP 连接个数有限制,一般是 6 - 8 个,那么可以把不同的静态资源放在不同的域名下,提升并发连接上限
- 引入雪碧图:将多张小图合并成一张大图供浏览器 JavaScript 来切割使用,这样可以将多个请求合并成一个请求,但是带来了新的问题,当某张小图片更新了,那么需要重新请求大图片,浪费了大量的网络带宽
- 将小图内联:将图片的二进制数据通过 base64 编码后,把编码数据嵌入到 HTML 或 CSS 文件中,以此来减少网络请求次数
.icon { background: url(data:image/png;base64,<data>) no-repeat; }
HTTP/2 新特性
2015 年,HTTP/2 发布。HTTP/2 是现行 HTTP 协议(HTTP/1.x)的替代,但它不是重写,HTTP 方法 / 状态码 / 语义都与 HTTP/1.x 一样。HTTP/2 基于 SPDY,专注于性能,最大的目标是在用户和网站间只用一个 TCP 连接。
Akamai 公司建立了一个官方 demo:【HTTP/2: the Future of the Internet】,同时请求 379 张图片,演示 HTTP/2 相对于 HTTP/1.1 在性能上的提升,可以从通过该链接的 demo 直观感受下 HTTP/2 比 HTTP/1.x 快了多少:
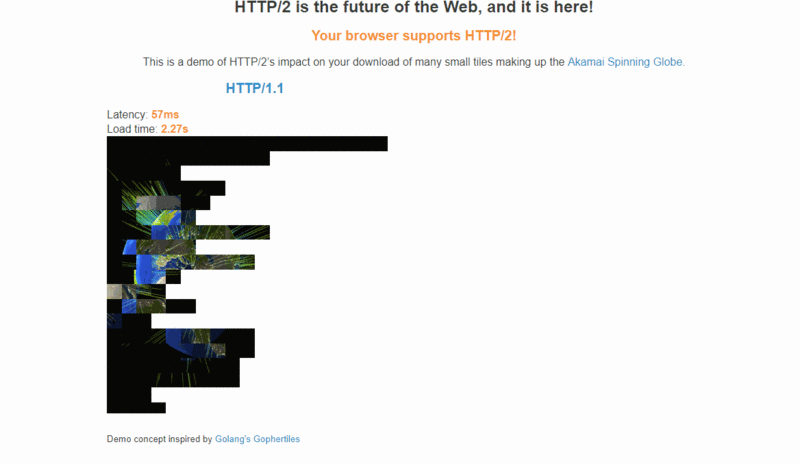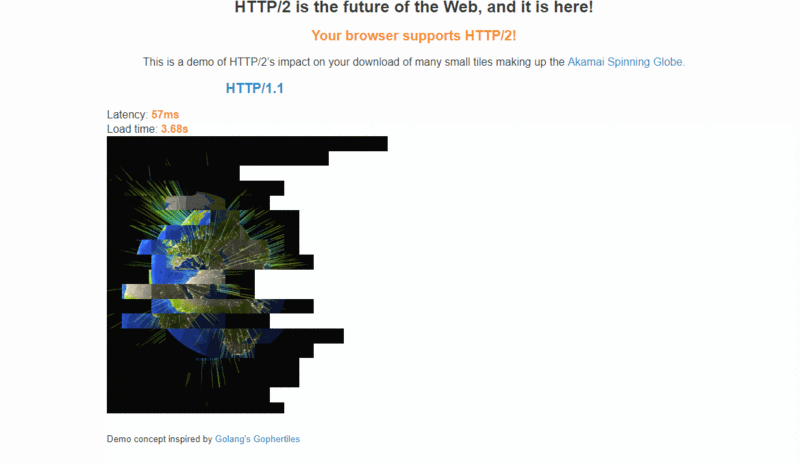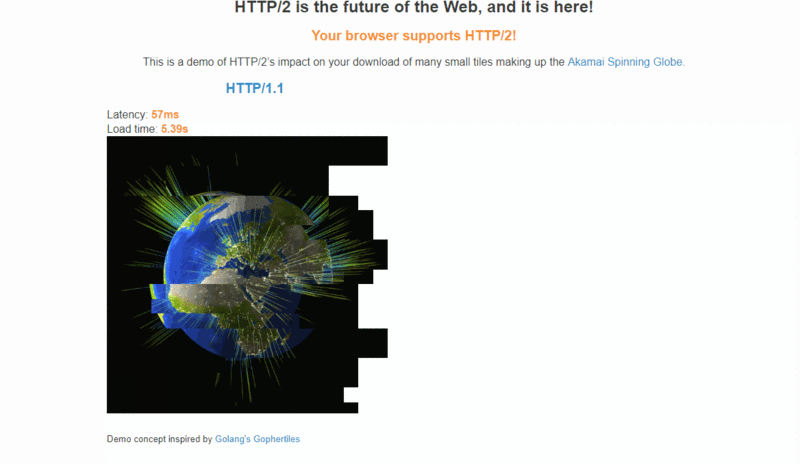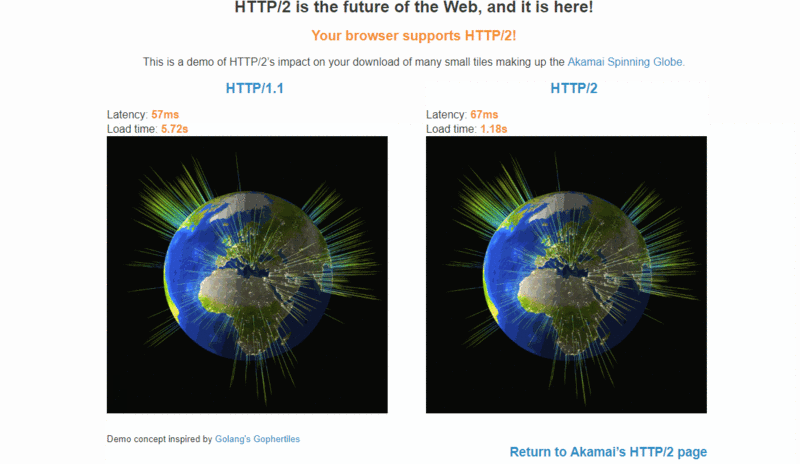
1. 二进制传输
在应用层(HTTP/2)和传输层(TCP or UDP)之间增加一个二进制分帧层。
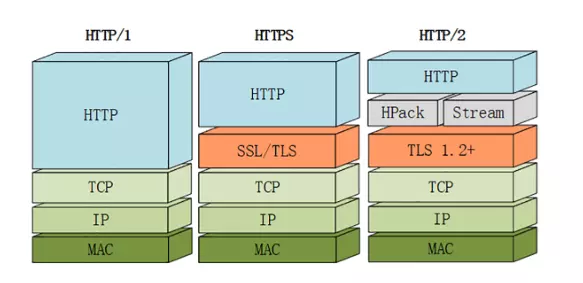
在二进制分帧层中, HTTP/2 会将所有传输的信息分割为更小的消息和帧(frame),并对它们采用二进制格式的编码,其中 HTTP1.x 的首部信息会被封装到 HEADERS 帧,而相应的 Request Body 则封装到 DATA 帧里面,HTTP/2 数据分帧后,“Header+Body”的报文结构就完全消失了,协议看到的只是一个个”碎片”。
HTTP/2 中,同域名下所有通信都在单个连接上完成,该连接可以承载任意数量的双向数据流。每个数据流都以消息的形式发送,而消息又由一个或多个帧组成。多个帧之间可以乱序发送,根据帧首部的流标识可以重新组装
2. Header 压缩(HPACK)
HTTP 协议不带有状态,每次请求都必须附上所有信息。所以,请求的很多字段都是重复的,比如Cookie和User Agent,一模一样的内容,每次请求都必须附带,这会浪费很多带宽,也影响速度。
HTTP/2 对这一点做了优化,引入了头信息压缩机制(header compression)。一方面,头信息使用 gzip 或 compress 压缩后再发送;另一方面,客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,以后就不发送同样字段了,只发送索引号,这样就提高速度了。
3. 多路复用(Multiplexing)
在 HTTP/2 中引入了多路复用的技术。多路复用很好地解决了浏览器限制同一个域名下请求数量的问题,同时也更容易实现全速传输,毕竟新开一个 TCP 连接都需要慢慢提升传输速度。
多路复用,就是在一个 TCP 连接中可以存在多条流。换句话说,也就是可以发送多个请求,对端可以通过帧中的标识知道属于哪个请求,这样就不需要等到前一个请求返回以后,才能发送下一个请求。
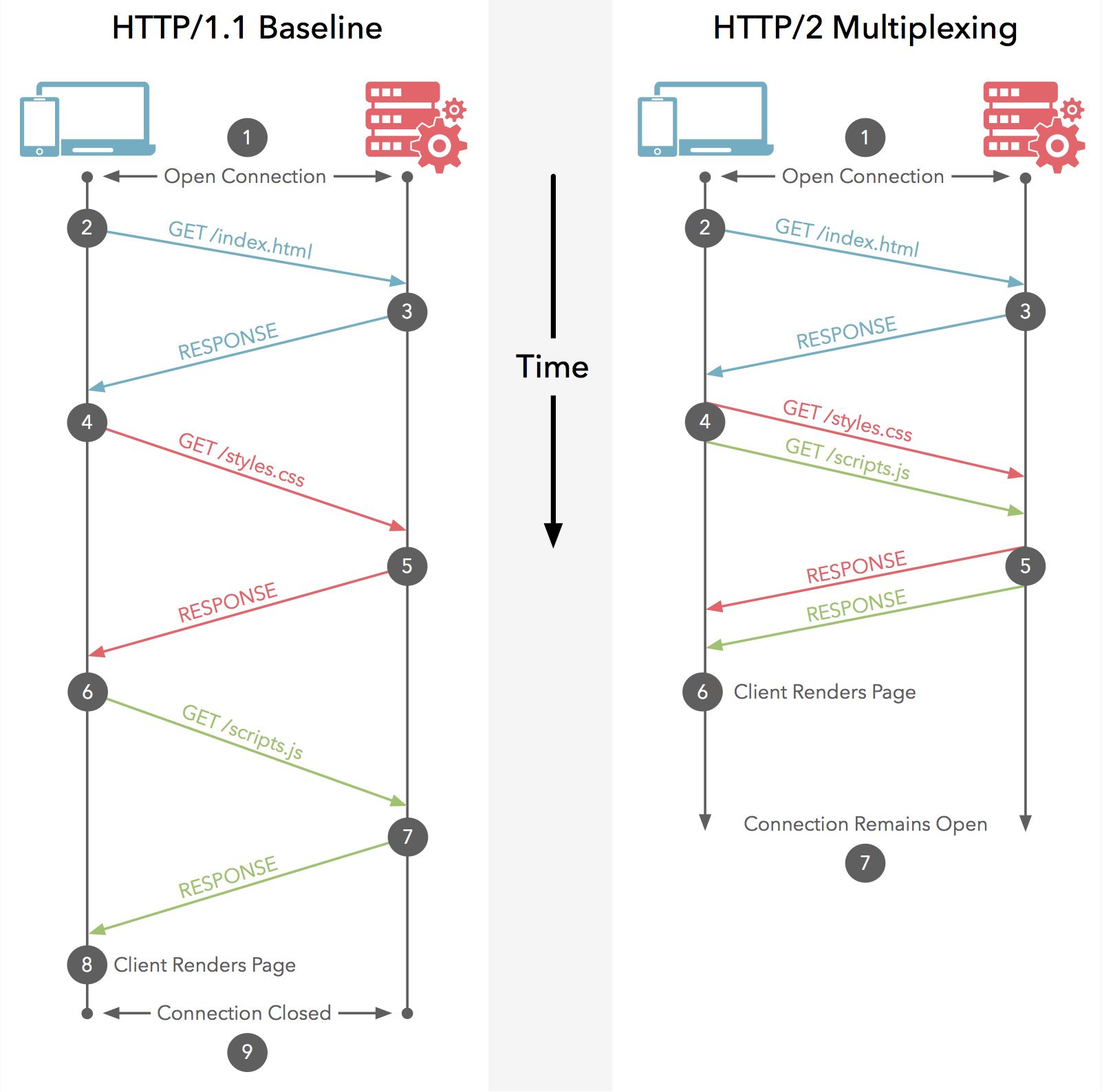
关键在于对数据包做标记,标识它属于哪个请求/响应。
HTTP/2 将每个请求或回应的所有数据包,称为一个数据流(stream)。每个数据流都有一个独一无二的编号。数据包发送的时候,都必须标记数据流ID,用来区分它属于哪个数据流。另外还规定,客户端发出的数据流,ID一律为奇数,服务器发出的,ID为偶数。
数据流发送到一半的时候,客户端和服务器都可以发送信号(RST_STREAM帧),取消这个数据流。1.1版取消数据流的唯一方法,就是关闭TCP连接。这就是说,HTTP/2 可以取消某一次请求,同时保证TCP连接还打开着,可以被其他请求使用。
在 HTTP/2 中,每个请求都可以带一个 31bit 的优先值,0 表示最高优先级, 数值越大优先级越低。有了这个优先值,客户端和服务器就可以在处理不同的流时采取不同的策略,以最优的方式发送流、消息和帧。
4. 服务端推送
HTTP/2 允许服务器未经请求,主动向客户端发送资源,这叫做服务器推送(server push)。
常见场景是客户端请求一个网页,这个网页里面包含很多静态资源。正常情况下,客户端必须收到网页后,解析 HTML 源码,发现有静态资源,再发出静态资源请求。其实,服务器可以预期到客户端请求网页后,很可能会再请求静态资源,所以就主动把这些静态资源随着网页一起发给客户端了。
注意: 服务端可以主动推送,客户端也可以主动选择是否接收,如果服务端推送的资源已经被浏览器缓存过,浏览器可以通过发送 RST_STREAM 帧来拒收,另外,主动推送也遵守同源策略。
总结
上面列出的 HTTP1.1 性能优化黑魔法的关键是低延迟,而不是高带宽,有了 HTTP/2 以后,有些黑魔法就可以抛弃不用了,比如雪碧图,当某张小图片更新了,那么需要重新请求大图片,浪费了大量的网络带宽,反而会降低性能。
HTTP/1.x 的 keep-alive 与 HTTP/2 多路复用的区别
基于上面介绍的 HTTP/1.1 长连接 和 HTTP/2 多路复用的原理,可以得出两者之间的区别:
-
HTTP/1.x 是基于文本的,只能整体去传;HTTP/2 是基于二进制流的,可以分解为独立的帧,交错发送
-
HTTP/1.x keep-alive 必须按照请求发送的顺序返回响应;HTTP/2 多路复用不按序响应
-
HTTP/1.x keep-alive 为了解决队头阻塞,将同一个页面的资源分散到不同域名下,开启了多个 TCP 连接;HTTP/2 同域名下所有通信都在单个连接上完成
-
HTTP/1.x keep-alive 单个 TCP 连接在同一时刻只能处理一个请求(两个请求的生命周期不能重叠);HTTP/2 单个 TCP 同一时刻可以发送多个请求和响应
HTTP/2 缺陷
HTTP/2 使用二进制传输、Header 压缩(HPACK)、多路复用等,相较于 HTTP/1.1 大幅提高了数据传输效率,但它仍然存在着以下几个致命问题(主要由底层支撑的 TCP 协议造成):
- 建立连接时间长
- HTTP/2 建立连接的时间 = TCP 建立连接时间(三次握手) + TLS 连接时间 (四次握手)
- 队头阻塞问题相较于 HTTP/1.1 更严重
- 因为 HTTP/2 使用了多路复用,一般来说同一域名下只需要使用一个 TCP 连接。当这个连接中出现了丢包的情况,那就会导致 HTTP/2 的表现情况反倒不如 HTTP/1 了。
- 因为在出现丢包的情况下,整个 TCP 都要开始等待重传,也就导致了后面的所有数据都被阻塞了。但是对于 HTTP/1 来说,可以开启多个 TCP 连接,出现这种情况反到只会影响其中一个连接,剩余的 TCP 连接还可以正常传输数据。
为了改善以上的问题,就有了 HTTP/3, HTTP/3的详细介绍可以参考下一篇文章:【HTTP/3 新特性】