最近在项目组里做了一个 session 分享怎么用 NgRx,以及 NgRx 的优势是什么。大家反馈很不错,写篇文章记录下这次的分享内容。
在这篇文件里会介绍以下内容:
- 什么是 NgRx
- 结合 Demo 代码,介绍 NgRX 的基本用法
- 从函数编程的角度来看,NgRx 的优势是什么
什么是NgRx
NgRx 是 state management library,是一个状态管理包,你也可以理解它是 RxJS 和 Redux 的结合体。
在真正开始解释什么是 NgRx 以及它的用法,先来看一个很简单的 NgRx 例子:有个搜索页面,在搜索框里输入关键字,可以查询到 Github 里相关的用户,并把这些用户显示在搜索结果页面,整体的效果如下:
这个 Demo 的代码在这里:【LiMeii/angular-ngrx】
如果 NgRx 是一个 state 管理包,那什么是 state 呢?state 是一个 JS 对象。以上面这个 Demo 为例,在输入关键字后,用户按下 Enter 键,会触发 Github User 的 API, 把 Github 用户名字里有这个关键字的所有用户的信息返回给前端,显示在页面上,那么这里的用户信息其实就是状态,它就是一个纯 JS 对象。
NgRx 的核心是 state(即 JS 对象),那怎么管理 state 对象呢?NgRx 是通过:actions effects reducers selector 管理 state,下面这张图里显示了这几个之间的关系:
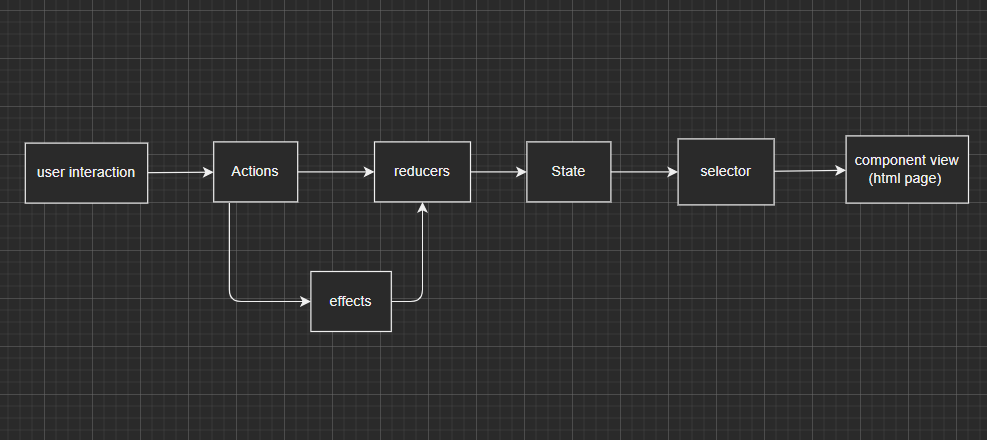
从上图中我们可以看到:
-
如果需要读取 state 里的数据,并把这些数据显示到页面上(component view),必须要通过
selector这个函数; -
如果需要更新 state 这个对象的值,那就必须通过
reducer这个函数; -
那怎么触发
reducer这个函数执行呢?必须要通过Action触发reducer函数执行; -
如果有异步事件要更新 state 的值呢?比如我们这个 demo 例子中,是通过 call GitHub 的 user API 拿到相关用户信息,那这些异步事件(API call)就可以写在 effects 里,在 API response 回来以后,再触发
Action,从而触发reducer函数去更新 state 的值; -
那
Action是谁来触发的呢?有两种方式:一种是用户的交互操作,比如上面这个例子里,用户输入关键字后,按下 Enter 键,触发一个 search action;还有一种方式是在 effects 里,在异步事件 callback 回来以后,触发一个 search success action;
再详细介绍什么是 actions effects reducers selector之前, 我们先来总结下整个事件执行的流程:用户在 search input 里输入关键字,按下 Enter 键,会触发一个 search action,在 effects 里去 call GitHub user API,这个 API response 回来以后,触发一个 search success action,这个 action 会触发 reducer 函数执行更新 state 的值,state 更新以后,会把更新后的值,通过 selector 这个函数,推送给页面(component view),component 拿到最新的 state 值后,把这些值更新显示在页面上。
大家有没有发现,整个流程,是从图中左边的用户交互(user interaction)开始,到图中右边的页面(component view)结束;如果页面又有新的用户交互操作,会重复从左到右的这个流程。这个流程叫做单向数据流(unidirectional data flow),也就是在更新操作 state 这个对象值的时候,必须要严格按照这个单向数据流的方式去做。为什么要这么做呢?其实最开始提出这种管理更新 state 对象的方式是由 Facebook 提出来的,叫 【Flux pattern】,因为这个话题也非常的大,不在我们这次讨论的范围里,大家有兴趣可以去看看它的官方文档的介绍。简单来说就是,通过这种单向数据流的方式管理对象的值,可以保证对象的唯一性和正确性,从而可以避免一些数据不一致的 bug。Flux pattern 特别适合用在中大型复杂的应用里。
简单来说,NgRx 是一个通过 actions effects reducers selector 这些事件函数来管理(更新、读取)state 对象的 library。
如何使用NgRx来管理state
了解什么是 NgRx 以后,怎么用它呢?具体代码是如何写的呢?我们还是以上面的 demo 为例,来看看怎么用 NgRx 实现一个简单的 GitHub 用户搜索功能。
state
我们之前讲过,state 实际就是一个 JS 对象,那么我们来看看具体代码是怎么定义和初始化 state:
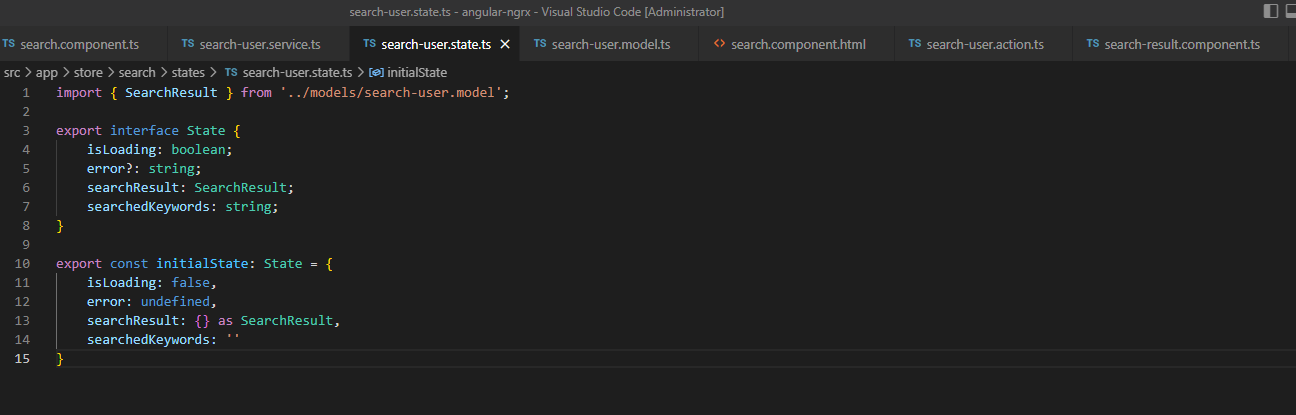
很简单,先定义一个 state 的结构(interface)然后初始化一下就可以。
selector
定义好 state 后,假设这个 state 里有值,怎么把这个 state 里的 searchResult(用户信息)显示到页面上呢?我们必须通过 selector 这个纯函数,读取 state 对象的值,拿到 searchResult 后,把这个数据推送给页面,我们来看下如果定义这个 selector:
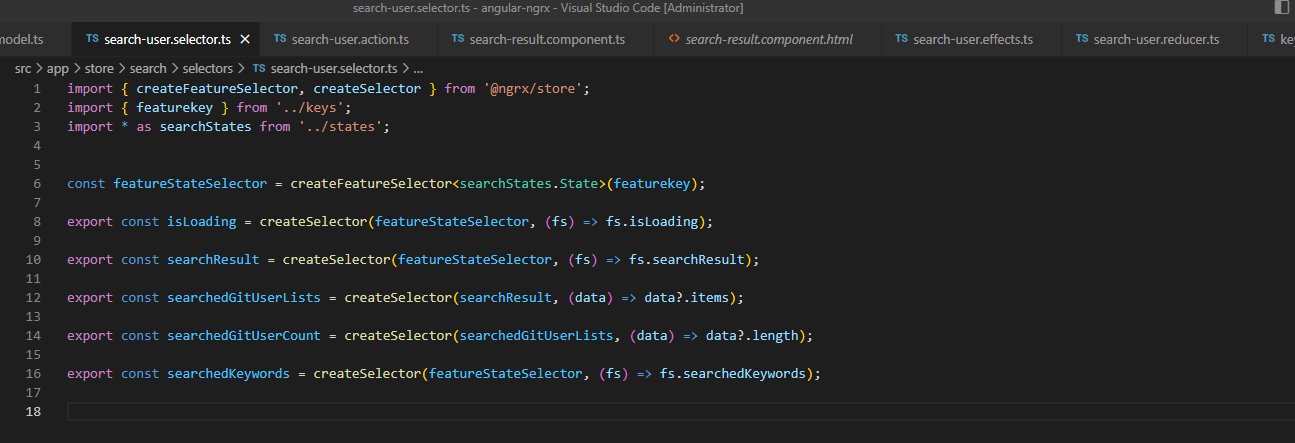
isLoading searchedKeywords 这两个我们先不看,主要看下 searchResult 相关的,其实也很简单,通过createFeatureSelector<searchStates.State>(featurekey) 拿到整个对象的值,因为真正的用户信息是在 state.searchResult.items 这个对象结构里,所以通过createSelector(featureStateSelector, (fs) => fs.searchResult); 拿到 searchResult 对象,然后通过createSelector(searchResult, (data) => data?.items) 拿到 用户信息 list。
如何把用户信息推送给页面
定义好 selector 函数读取用户信息 list,怎么把这些数据推送给页面呢?其实也很简单,在页面里 订阅用户信息就可以了,之前有讲过 NgRx 是基于 RxJS 的,所有的数据操作都是 Observable,页面代码如下:
component 代码如下:
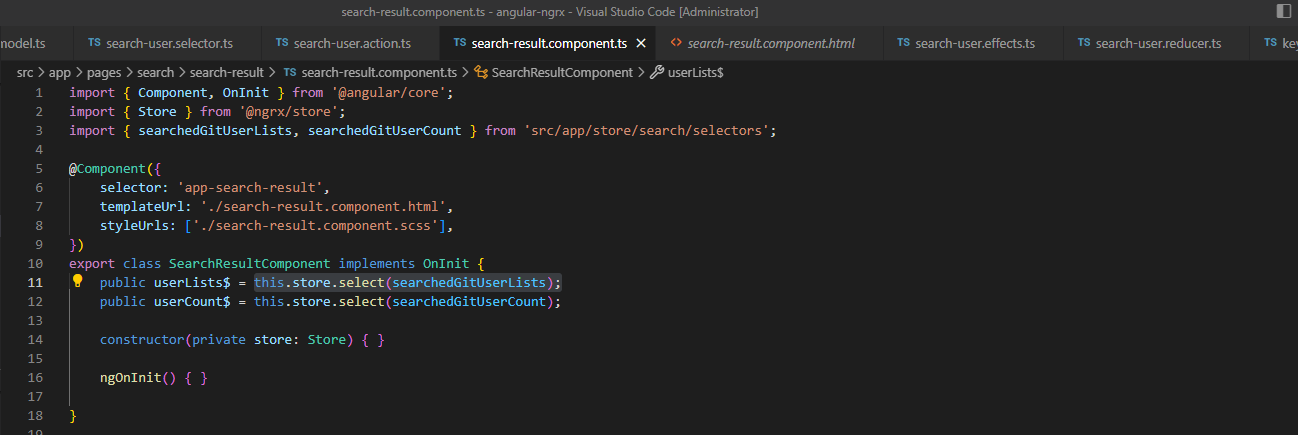
html 页面代码如下:
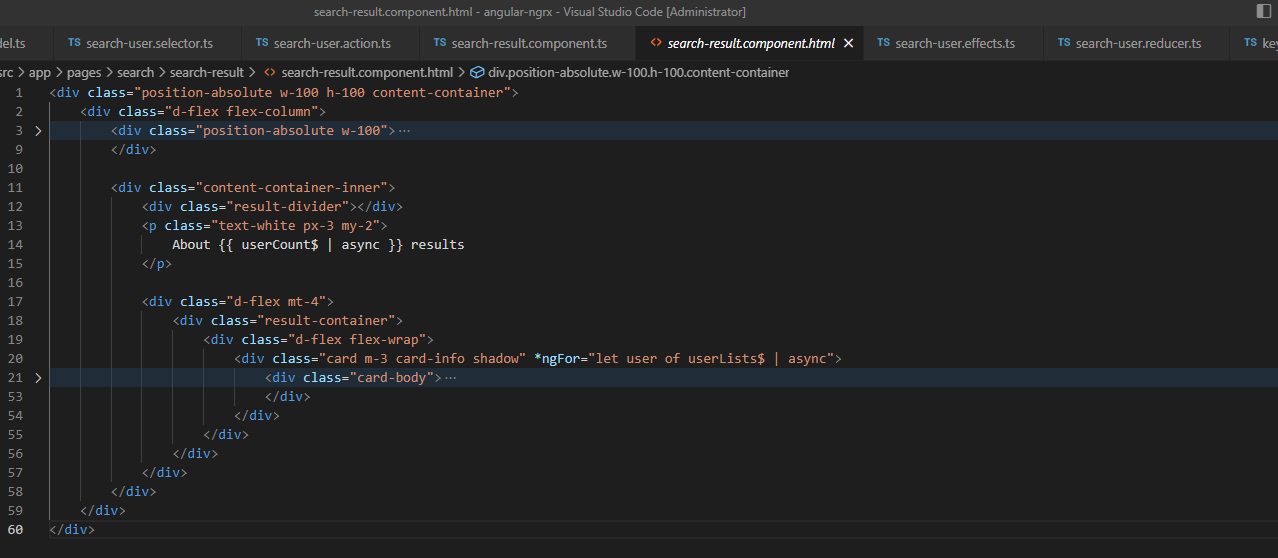
在 compoent 里,this.store.select(searchedGitUserLists);是订阅用户信息 Observable,在 html 页面里 通过 *ngFor="let user of userLists$ | async" async pipe 读取 userLists$ 并把用户信息循环显示在页面上。
action
我们之前介绍过,如果想要更新 state 对象的值,必须由用户交互操作触发 action 或者 effects 的异步操作 callback 之后触发 action,再由 action 去触发 reducer 函数更新 state 的值。
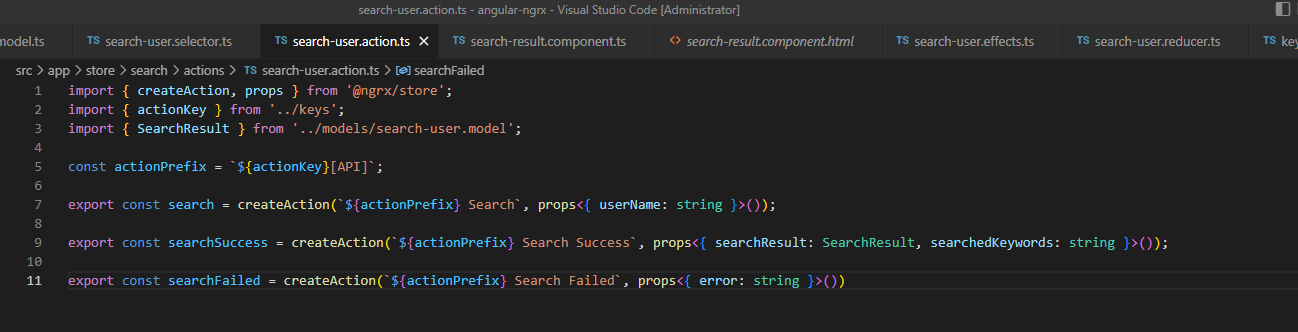
那什么是 action 呢? action 是所有可以改变 state 的操作。比如以我们这个 demo 为例,用户输入关键字以后,按下 Enter 键,这个操作会改变 state 的值,我们可以把这个操作定义为 search action; API callback 回来以后,需要把 API response 回来的值更新到 state 里,我们可以把这个操作定义为search success action;如果 API call 失败,我们要把错误信息更新到 state 里,可以把这个操作定义为 search failed action。具体代码如下:
effects
所有的异步操作,比如常用的 API call,需要放在 effects 里,我们来看下具体代码写法:
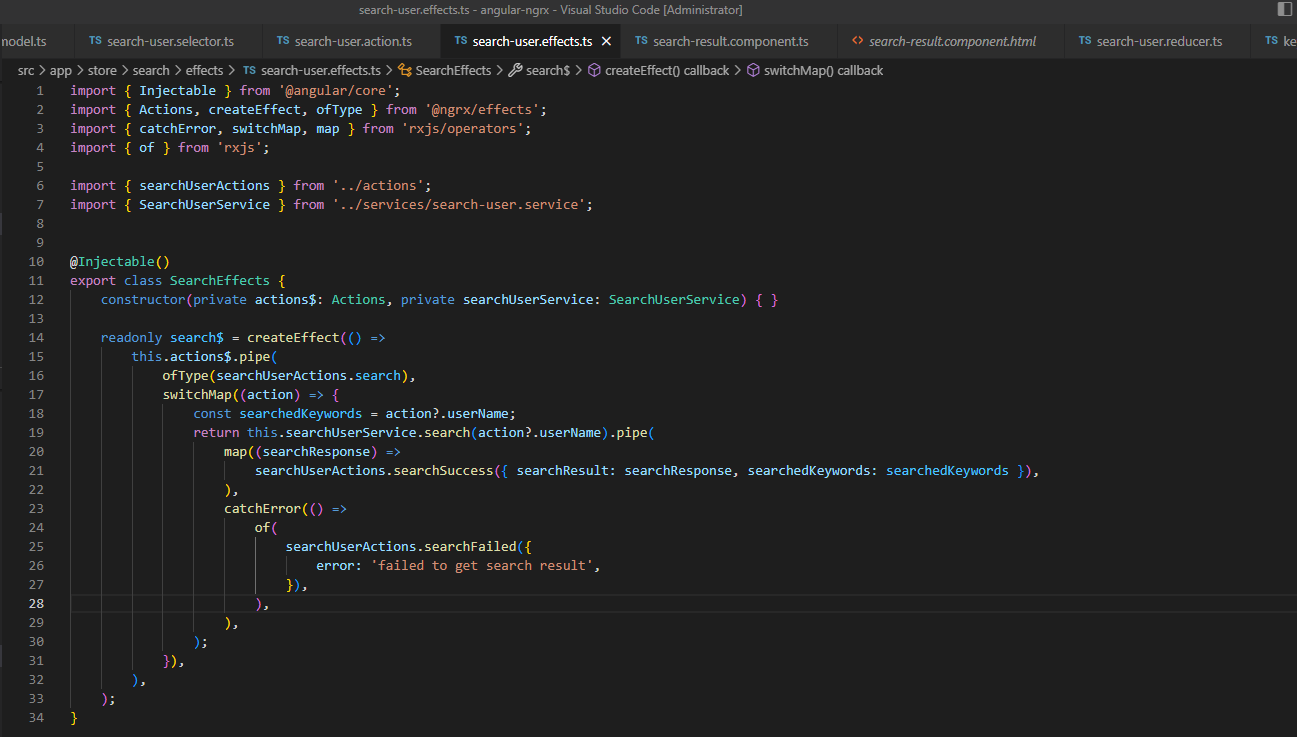
代码this.actions$.pipe( ofType(searchUserActions.search)表示监听所有 action 事件,如果是 search action 就触发 API call,如果 API call success,触发 search success action:searchUserActions.searchSuccess;如果 API call failed,触发 search failed action:searchUserActions.searchFailed.
reducer
有了 action 和 effects,那么如何执行 reducer 去更新 state 呢?代码如下:
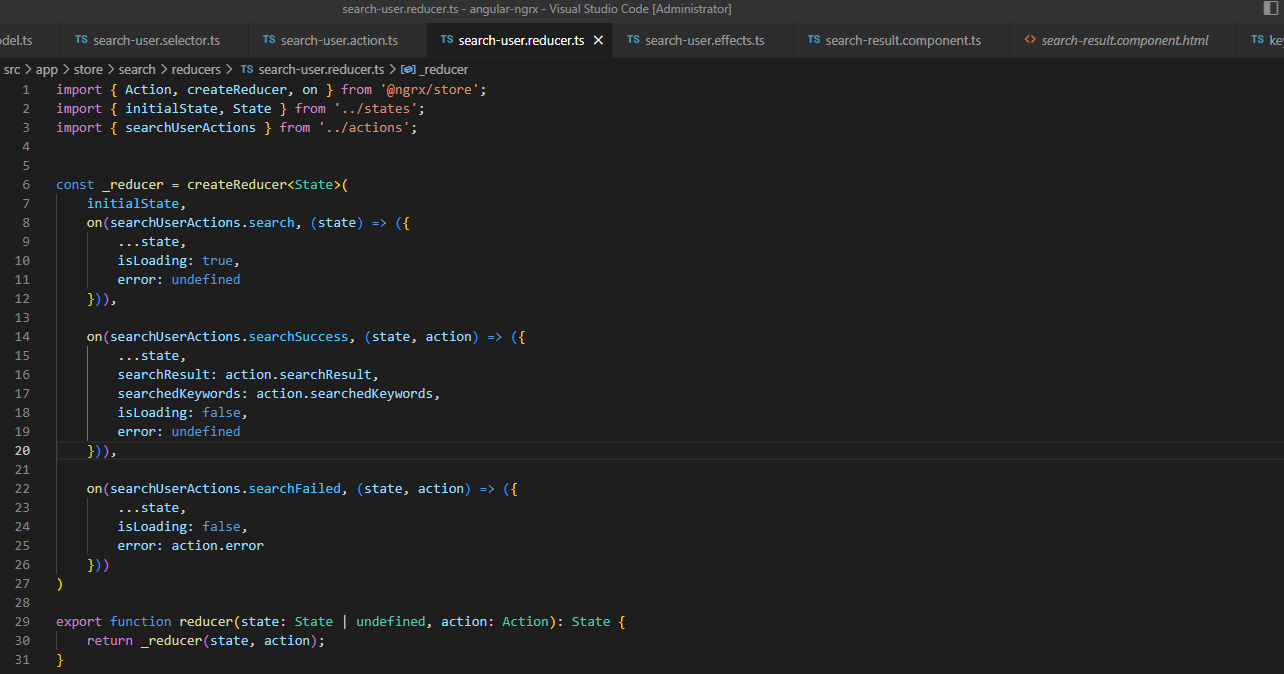
从代码里可以看到,通过监听所有的 action,一旦 action 发生,通过 ES6 的两个语法(展开和解构)返回一个新的 state 对象。
用户交互如何触发action
我们知道用户操作可以触发 action,那再用户按下 Enter 后,怎么来触发 search action 呢?
 其实也很简单,一行代码就可以
其实也很简单,一行代码就可以this.store.dispatch(searchUserActions.search({ userName: this.searchVal?.trim() }))
NgRx的优势
看完上面如何用 NgRx 实现一个简单的 search GitHub 用户信息功能的代码,大家有没有觉得,用这种方式写代码,很繁琐,要定义很多文件,而且大部分都是把业务代码套用在 NgRx 的模板代码里。为什么一定要用actions effects reducers selector去管理 state,代码这么繁琐,为什么大家都在力荐使用 state 这种模式开发,它为什么要这么写,又有什么优势呢?
NgRx 是一个 state manage library,整个包的编程思路都是基于函数编程写的;要理解 NgRx 的优势,可以从函数编程这个角度来看,搞清楚函数编程之后,就能理解为什么要这么写代码,以及这么写代码的优势是什么。
函数编程
函数编程(functional programming)是一个很大的话题,完全讲清楚函数编程并不在我们这篇文章的范围里,在这篇文章里就简单介绍下函数编程的三个核心概念,让大家理解下什么是函数编程,以及它的优势是什么。
函数编程是一种编程思维,它有三个核心概念:纯函数(Pure Function)、不可更改的 state(Immutable State)、副作用(Side Effect)
Pure Function
什么是纯函数呢,为什么要用纯函数,它的优势是什么呢?
官方的对纯函数的解释是:如果一个函数,在入参一致的情况下,不管这个函数调用多少次,返回结果永远一样,那么这个函数就是纯函数。这么一看,是不是感觉一头雾水,解释了跟没解释一样,我们来看下具体的例子:
//Pure function
function add(a,b){
return a + b;
}
//Impure function
function random(){
return Math.random();
}
//Impure function
function sayHello(name){
console.log("Hello " + name);
}
以上有三个函数,第一个是纯函数,另外两个不是。
先来看第一个函数,如果 a=1, b=1, 那么不管是调用这个函数多少次,永远返回 1+1 等于2,不可能会返回其他值,这个函数是纯函数。
第二个函数,返回值是随机的,不符合纯函数的定义,它不是纯函数。
第三个函数,在函数里调用了 I/O 操作console.log,它也不是纯函数,不仅如此,如果在函数内部调用了 I/O,或者调用了 API,或者在当前函数里改了函数作用域外面的值,都不是纯函数。
纯函数有什么优势呢?
1. 可读性好
纯函数不会调用 I/O,不会调用 API,也不会改作用域外的值,那么代码就容易读懂,可读性好
2. 易维护
同上,因为不会调用 I/O,不会调用 API,也不会改作用域外的值,那么也容易维护
3. 缓存功能
可以有缓存的功能,这个要怎么理解呢?假如一个纯函数用来做计算,返回计算结果,如果计算逻辑非常非常复杂,代码执行完这些计算逻辑都要一分钟。假如有这样一种情形,每次调用这个复杂计算函数的入参都是一样的,每次都执行一分钟才能拿到计算结果,是不是有点性能浪费,那么在这种情况下,我们可以在第一次执行这个复杂计算函数的时候,就把计算结果缓存起来,后面同样入参调用这个复杂计算函数就可以直接从缓存里读取结果,而不需要每次都去执行这个复杂函数,这样就大大提升了代码的性能。
这跟我们 NgRx 有什么关系呢?前面说过 NgRx 是函数编程的实现,它的 reducer selector 都是纯函数。我们现在这个搜索 GitHub 用户的例子,业务逻辑比较简单,看 selector 代码都是直接读取 state 里面变量的值。但是大家可以想象下,如果有个业务需要非常复杂的计算,拿到某个 state 变量以后,需要执行一个非常复杂的计算,然后再返回这个计算结果,推送给页面显示。那么这个情况,就可以用缓存的优势,因为 selector 这个纯函数入参是一样的,那么第一次执行 selector 纯函数的时候,把这个复杂计算结果缓存起来,后续其他页面要用到这个计算结果的时候,就可以直接从缓存里读取这个值,不需要每次都去执行这个复杂计算逻辑了,从而可以提高性能。
Immutable State
不可更改的 state,之前看 reducer 代码,明明都是一旦有 action 发生的时候,就会触发 reducer 函数去更新 state,这里怎么又说 state 是不可更改的呢?
在解释这点之前,先讲个大家都知道的事情:我们都知道对象在内存里存储的时候,是存的引用,如果要比较一个对象是否相等,需要两个步骤,首先要比较引用是否一样,如果引用一样,再去对比引用指向的属性和值是否一样,只有引用、引用指向的属性和值都一样的情况下,这两个对象才相等。
那么我们日常在写代码的时候,如果要改变一个对象某个属性的值,一般有以下两种写法:
let user = { username:"admin", age:28 }
// 1
user.age = 30;
// 2
let newUser = {...user, age:29 }
第一种写法,没有改原来 user 对象的引用,只改了属性 age 的值;第二种写法是用了 ES6 的新语法(展开和解构),这两个语法执行以后的结果是,创建了一个全新的对象 newUser(完全新的引用)把没有改的属性 username 以及它的值(admin) copy 过来,同时把 age 这个属性的值设置为 29。
这两种写法的区别:第一个没有改引用,只是改了引用指向的属性值,第二个是创建了全新的引用。从 reducer 的代码可以看到 state 的更新都是用的第二种写法,每次更新 state 都是创建新的 state 对象,不会改老的 state 对象,从这个角度来看,老的 state 对象就是不可更改的。
那么如果有个对象很复杂,对象属性指向的也是一个对象,层层嵌套了好几个对象属性。这个时候需要判断这个对象的有没有被更改,这两个写法哪个的效率更高呢?明显可以看出来第二种的效率更高,之前说过对比两个对象是否相等,第一步是比较引用是否一样,如果引用一样,再去递归遍历指向的属性对象是否一样。第二种写法,直接创建了新引用,那么在判断对象是否有更新的时候,发现引用不一样就不需要再去递归遍历指向的值是否相等了。
Angular change detection 发生的时候,会去遍历 component view 绑定的对象,去看对象的值有没有发生改变,如果有更新就把这个新的值,重新渲染到页面上。如果这个绑定的对象结构很复杂,层层嵌套了很多对象属性,如果每次只改了一个属性的值,change detection 发生的时候,还是需要递归遍历所有属性,这种方式很浪费性能。
用了 NgRx 这种 state 更新方式,每次都创建新的引用(牺牲空间换取更短的时间,以空间换时间),那么再判断绑定对象是否有更新的时候,发现引用不一样,就可以把新的对象渲染到页面上。
Immutable State 除了这个性能优势之外,还有个优势是,因为每次更新 state 对象都是创建一个新的对象,原来的对象都在内存里,相当于所有的 history 都在内存里,那么我们可以 undo、redo 这个改动,像 state 的 devtools 就是基于这一点实现的。
Side Effect
之前说过,所有的异步事件(比如 API call)都需要放在 effects 里。这么写有什么好处呢?
把 API call 从页面 component 代码里解耦出来,页面 component 只负责数据的呈现,不需要去关心这个数据是从哪里来的,以及怎么处理这些数据,那么页面 component 代码就简单很多了,不需要注入 service,只负责数据呈现,代码可读性就高,而且 Unit Test 就简单很多,不需要 mock 每个依赖注入的 service。
NgRx优势
NgRx 是函数编程的一种实现,理解了函数编程的优势以后,就能理解 NgRx 的优势了:
-
共享 state:state 是共享的且唯一,不同的页面都是从一个 state 对象里读取值,这样可以保证 state 对象的准确性和唯一性。
-
纯函数:reduer 和 selector 都是纯函数,代码可读性强、容易维护、利用缓存提高性能
-
不可更改的 state:每次更新 state 对象,都是创建全新的对象引用,大大提高判断对象是否更新的性能,从而提高了 change detection 的性能
-
副作用:把异步事件代码(API call)和页面数据呈现代码解耦,提高代码可读性、容易维护、容易写单元测试